ś╦(bi©Īo)Ņ}Ż║FPGAģf(xi©”)╠Ä└Ē╝╝ąg(sh©┤)ĮķĮB╝░▀M(j©¼n)š╣
’@╚╗Ż¼F(xi©żn)PGAį┌▓óąą╗»┼c┴„╦«╗»ĘĮ├µ┤µį┌ŽÓ«ö(d©Īng)┤¾Ą─ā×(y©Łu)ä▌(sh©¼)Ż¼═¼Ģr(sh©¬)┼cGPGPUŽÓ▒╚Ż¼F(xi©żn)PGAį┌ų„ŠÅ┤µ┼cĦīÆĘĮ├µę▓┤µį┌ā×(y©Łu)ä▌(sh©¼)ĪŻį┌FPGAųąŻ¼▀ē▌ŗ┘Yį┤ų▄ć·╩Ū┤µā”(ch©│)Ų„ēKĪŻXDI─ŻēKŠ▀ėąę╗ēKĦīÆ×ķ3.8TB/sĄ─3.3MBų„ŠÅ┤µŻ¼▀@╩ŪnVidia 8800 GTXą═GPGPU╔Žų„ŠÅ┤µ(ų¦│ų┴„╠Ä└ĒŲ„)Ą─5Ī½10▒ČĪŻ
FPGAĄ─ā×(y©Łu)ä▌(sh©¼)▀Ćį┌ė┌Ż¼┐╔ęį└¹ė├įŻ┴┐▀BĮėĦīÆüĒņ`╗Ņśŗ(g©░u)Į©ų▒▀_(d©ó)Ė„▀ē▌ŗēKĄ─öĄ(sh©┤)ō■(j©┤)═©Ą└║═┤µā”(ch©│)Ų„įLå¢═©┬ĘĪŻłD1╦∙╩ŠĄ─┐╔ŠÄ│╠╗ź▀BĮY(ji©”)śŗ(g©░u)╠ß╣®┴╦┤¾┴┐Ą─▓╝ŠĆĦīÆĪŻ─ŻēK┼cļŖ┬Ę░Õ┐╔Ė∙ō■(j©┤)FPGA▌ö│÷ĦīÆĪó┤µā”(ch©│)Ų„┤¾ąĪ╝░čė▀tĄ─ąĶę¬▀M(j©¼n)ąąįO(sh©©)ėŗ(j©¼)Ż¼I/OČ╦┐┌┐╔ė╔ė├æ¶ūįČ©┴xĪŻ

łD1 FPGAĄ─╝▄śŗ(g©░u)
ūŅ║¾Ż¼F(xi©żn)PGA╝▄śŗ(g©░u)▀ĆōĒėąę╗éĆ(g©©)ā×(y©Łu)ä▌(sh©¼)Ż¼╦³┐╔öU(ku©░)š╣×ķĖ³┤¾ą═Ą─▀ē▌ŗēKĪó┤µā”(ch©│)Ų„ēK┼cDSPēKĄ─Ļć┴ąĪŻ▀ē▌ŗ┼cų„ŠÅ┤µĄ─┤¾ąĪ╩Ūę╗ŲöU(ku©░)š╣Ą─ĪŻ¼F(xi©żn)ėąūŅ┤¾Ą─FPGAĘÕųĄ╣”║─×ķ30WŻ¼ŲõFPGA╝▄śŗ(g©░u)ėą║▄ČÓ┐šķgŻ¼┐╔ęįį┌▓╗│¼▀^¼F(xi©żn)ėąöĄ(sh©┤)ō■(j©┤)ųąą─╣”┬╩║═└õģsŽ▐ųŲĄ─Ū░╠ߎ┬Ż¼öU(ku©░)š╣×ķą┬Ą─╠Ä└Ēśŗ(g©░u)ą═ĪŻ
▒M╣▄FPGA╝▄śŗ(g©░u)Š▀ėąįSČÓ│÷▒ŖĄ─ąį─▄Ż¼ę╗ą®ąį─▄▒žĒÜ╣▓═¼░l(f©Ī)ō]ū„ė├Ż¼▓┼─▄╠ß╣®ā×(y©Łu)ė┌CPUģf(xi©”)╠Ä└ĒĄ─ĮŌøQĘĮ░ĖĪŻ
ąŠŲ¼┼c╦ŃĘ©╗∙ĄA(ch©│)
┤¾▓┐ĘųļpŠ½Č╚ĖĪ³c(di©Żn)╦ŃĘ©Ą─╝ėĘ©┼c│╦Ę©▓┘ū„▒╚└²┤¾╝s×ķ1:1ĪŻį┌FPGAųąŻ¼╝ėĘ©▀\(y©┤n)╦Ń╩╣ė├▀ē▌ŗ┘Yį┤Ż¼│╦Ę©▀\(y©┤n)╦Ń╩╣ė├DSPēKŻ¼ę“┤╦FPGAĄ─▀ē▌ŗ┘Yį┤┼cDSPēKĄ─▒╚└²▒žĒÜŠ∙║ŌĪŻFPGAĄ─┴Ēę╗éĆ(g©©)╠ž³c(di©Żn)╩ŪŲõ┐╔ŠÄ│╠╣”┬╩╝╝ąg(sh©┤)Ż¼įō╝╝ąg(sh©┤)┐╔ßśī”(du©¼)╦∙ėą▀ē▌ŗēKĪóDSPēK┼c┤µā”(ch©│)Ų„ēK▀M(j©¼n)ąąŠÄ│╠Ż¼Ė∙ō■(j©┤)įO(sh©©)ėŗ(j©¼)Ą─Ģr(sh©¬)ą“ę¬Ū¾īóŲõįO(sh©©)Č©×ķĖ▀╣”║─╗“Ą═╣”║──Ż╩ĮĪŻ
ĖĪ³c(di©Żn)▀\(y©┤n)╦Ń║╦ęčĮø(j©®ng)Ė─▀M(j©¼n)Ż¼┐╔▀\(y©┤n)ąąė┌Ė³Ė▀Ą─Ģr(sh©¬)ńŖ╦┘┬╩Ż¼╩╣ė├Ė³╔┘Ą─DSPēK║═Ė³╔┘Ą─▀ē▌ŗ┘Yį┤ĪŻ▓╔ė├ĖĪ³c(di©Żn)ŠÄūgŲ„┐╔£p╔┘▓╗═¼ĖĪ³c(di©Żn)▀\(y©┤n)╦Ń║╦ų«ķgė├ė┌▀BĮė64╬╗öĄ(sh©┤)ō■(j©┤)═©┬ĘĄ─▀ē▌ŗ┘Yį┤ĪŻ
į┌ę╗┤╬ĖĪ³c(di©Żn)▀\(y©┤n)╦ŃĮY(ji©”)╩°Ģr(sh©¬)Ż¼║Ž▓óī”(du©¼)ĖĪ³c(di©Żn)▀\(y©┤n)╦Ń▀M(j©¼n)ąąęÄ(gu©®)Ė±╗»╠Ä└Ē(Č©³c(di©Żn)Ė±╩Į▐D(zhu©Żn)ōQų┴ĖĪ³c(di©Żn)Ė±╩Į)Ą─▓Į¾EŻ¼┐╔ęį’@ų°£p╔┘ī”(du©¼)║¾└m(x©┤)ĖĪ³c(di©Żn)▀\(y©┤n)╦Ń▌ö╚ļĄ─╚źęÄ(gu©®)Ė±╗»╠Ä└Ē(ĖĪ³c(di©Żn)Ė±╩Į▐D(zhu©Żn)ōQ×ķČ©³c(di©Żn)Ė±╩Į)ĪŻĖĪ³c(di©Żn)▀\(y©┤n)╦ŃĄ─öĄ(sh©┤)īW(xu©”)▒Ē▀_(d©ó)╩ĮĄ─š¹éĆ(g©©)öĄ(sh©┤)ō■(j©┤)═©┬Ę┐╔╚█Įėį┌ę╗ŲŻ¼▀@Ģ■(hu©¼)ūŅČÓ£p╔┘40%Ą─▀ē▌ŗ┘Yį┤▓ó╩╣Ģr(sh©¬)ńŖ╦┘┬╩┬įėą╠ßĖ▀ĪŻ
ĖĪ³c(di©Żn)▀\(y©┤n)╦ŃĄ─š²┤_ĮM║Ž╩«Ęųųžę¬ĪŻ╚ń╣¹╦ŃĘ©ėąįSČÓ│¼įĮ▀\(y©┤n)╦Ń(Ū¾ųĖöĄ(sh©┤)ĪóŪ¾ī”(du©¼)öĄ(sh©┤)Ą╚)Ż¼F(xi©żn)PGA┐╔┼õų├╦∙ąĶꬥ─öĄ(sh©┤)─┐ĪŻį┌GPGPUįO(sh©©)ėŗ(j©¼)ųąŻ¼Ģ■(hu©¼)į÷╝ėę╗ą®ė▓─ŻēKīŹ(sh©¬)¼F(xi©żn)╔Ž╩÷║»öĄ(sh©┤)Ż¼Ą½▒╚└²▒╚å╬Š½Č╚ĖĪ³c(di©Żn)▀ē▌ŗ╔┘Ą├ČÓĪŻ╩╣ė├╦ŃĘ©╝╝Ū╔Īó│ķŽ¾ė▓╝■╝Ü(x©¼)╣Ø(ji©”)╝░ßśī”(du©¼)éĆ(g©©)äeFPGA┘Yį┤Ą─ā×(y©Łu)╗»Č╝ąĶę¬║»öĄ(sh©┤)ÄņĪŻ
╗∙ė┌ąŠŲ¼Īó╦ŃĘ©┼cÄņ╗∙ĄA(ch©│)Ż¼łD2Ą─ŽĄĮy(t©»ng)╝ē(j©¬)ĮŌøQĘĮ░Ė╔µ╝░ĄĮ┴╦╣żŠ▀µ£Īó─ŻēK/░Õ╝ē(j©¬)įO(sh©©)ėŗ(j©¼)ĪóCPUĮė┐┌ęį╝░▓╔ė├║Žū„╣½╦ŠīŻķT╝╝ąg(sh©┤)Ą─ė╔CPUų┴╗∙ė┌FPGAĄ─╝ė╦┘Ų„Ą─öĄ(sh©┤)ō■(j©┤)é„▌öĪŻ
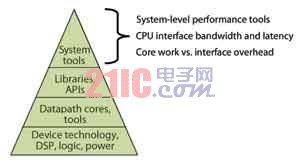
łD2 FPGA╝ė╦┘ŽĄĮy(t©»ng)╝ē(j©¬)ĮŌøQĘĮ░ĖĄ─╗∙ĄA(ch©│)